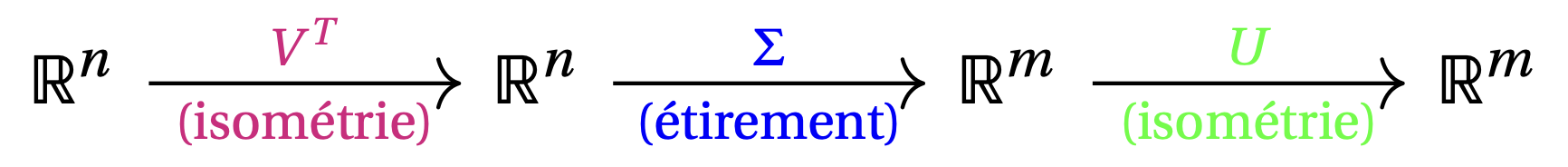
'' Today, singular value decomposition has spread through many branches of science, in particular psychology and sociology, climate and atmospheric science, and astronomy. It is also extremely useful in machine learning and in both descriptive and predictive statistics. ''
'' Eigenvalues and eigenvectors are restricted to square matrices. But data comes in rectangular matrices. ''
Si la diagonalisation a permis de comprendre la nature géométrique de certaines applications linéaires, elle exige malheureusement que l'application considérée se prête à cette analyse (qu'elle soit diagonalisable justement), et surtout: elle ne s'applique qu'à des matrices carrées.
La décomposition en valeurs singulières (en anglais, SVD\(=\)Singular Value Decomposition) est une méthode très générale de factorisation qui donne une nouvelle interprétation géométrique de n'importe quelle application linéaire \(T:\mathbb{R}^n\to\mathbb{R}^m\). Elle consiste à factoriser une matrice quelconque \(A\) de taille \(m\times n\) en un produit, \[ A= {\color{green}U} {\color{blue}\Sigma} {\color{magenta} V^T}\,, \] où
On sait d'une part que les matrices orthogonales représentent des isométries, c'est-à-dire des transformations rigides de l'espace, comme des rotations. D'autre part, une matrice diagonale de taille \(m\times n\) a pour effet d'étirer les vecteurs dans certaines directions (avec un changement de dimension, voir plus bas). Donc la décomposition en valeurs singulières permet de décomposer l'application \(T:\mathbb{R}^n\to\mathbb{R}^m\) définie par \(T(\boldsymbol{x})=A\boldsymbol{x}\) en trois parties:
Dans la section suivante, nous établirons rigoureusement la décomposition en
valeurs singulières. Pour l'instant, supposons qu'une décomposition
\[ A= U \Sigma V^T \]
soit donnée, et voyons ce que cela dit déjà sur les matrices \(U\),
\(\Sigma\) et \(V\).
Nommons les colonnes de \(V\), \(U\) et \(\Sigma\):
\[\begin{aligned}
U&=[\boldsymbol{u}_1 \cdots \boldsymbol{u}_m]\,,\qquad \boldsymbol{u}_k\in\mathbb{R}^m\,,\\
\Sigma&=[\boldsymbol{\sigma}_1 \cdots \boldsymbol{\sigma}_n]\,,\qquad \boldsymbol{\sigma}_i\in\mathbb{R}^m\,,\\
V&=[\boldsymbol{v}_1 \cdots \boldsymbol{v}_n]\,,\qquad \boldsymbol{v}_j\in\mathbb{R}^n\,.
\end{aligned}\]
Comme \(U\) et \(V\) sont orthogonales, les familles
\(\{\boldsymbol{u}_1,\dots,\boldsymbol{u}_m\} \subseteq \mathbb{R}^m\)
et
\(\{\boldsymbol{v}_1,\dots,\boldsymbol{v}_n\}\subseteq\mathbb{R}^n\)
sont orthogonales.
La matrice \(\Sigma\) représente une application \(\mathbb{R}^n\to\mathbb{R}^m\) dont la
simplicité rappelle celle des matrices diagonales carrées.
Nous noterons \(\sigma_i\) les éléments diagonaux de \(\Sigma\).
Notons que si \(m\gt n\) (resp., \(m\lt n\)),
alors certaines lignes (resp., colonnes) de \(\Sigma\) sont nulles.
Exemple: Si \(m=7\) et \(n=4\), alors les \(3\) dernières lignes de \(\Sigma\) sont nulles: \[ \Sigma= \begin{pmatrix} \sigma_1&0&0&0\\ 0&\sigma_2&0&0\\ 0&0&\sigma_3&0\\ 0&0&0&\sigma_4\\ {\color{red}0}&{\color{red}0}&{\color{red}0}&{\color{red}0}\\ {\color{red}0}&{\color{red}0}&{\color{red}0}&{\color{red}0}\\ {\color{red}0}&{\color{red}0}&{\color{red}0}&{\color{red}0}\\ \end{pmatrix}\,. \] Notons \(\mathcal{B}_{\mathrm{can}}\) et \(\mathcal{B}_{\mathrm{can}}'\) les bases canoniques de \(\mathbb{R}^4\) et \(\mathbb{R}^7\): \[\begin{aligned} \mathcal{B}_{\mathrm{can}}&=\{\boldsymbol{e}_1,\boldsymbol{e}_2,\boldsymbol{e}_3,\boldsymbol{e}_4\}\,,\\ \mathcal{B}_{\mathrm{can}}'&=\{ \boldsymbol{e}_1', \boldsymbol{e}_2', \boldsymbol{e}_3', \boldsymbol{e}_4', \boldsymbol{e}_5', \boldsymbol{e}_6', \boldsymbol{e}_7'\}\,. \end{aligned}\] L'application \(\boldsymbol{x}\mapsto \Sigma\boldsymbol{x}\) représente des ''stretches'' pour les \(4\) vecteurs de \(\mathcal{B}_{\mathrm{can}}\), \[ \Sigma\boldsymbol{e}_1=\sigma_1\boldsymbol{e}_1'\,,\quad \Sigma\boldsymbol{e}_2=\sigma_2\boldsymbol{e}_2'\,,\quad \Sigma\boldsymbol{e}_3=\sigma_3\boldsymbol{e}_3'\,,\quad \Sigma\boldsymbol{e}_4=\sigma_4\boldsymbol{e}_4'\,. \]
Exemple: Si \(m=3\), \(n=5\), alors les \(2\) dernières colonnes de \(\Sigma\) sont nulles: \[ \Sigma= \begin{pmatrix} \sigma_1&0&0&{\color{red}0}&{\color{red}0}\\ 0&\sigma_2&0&{\color{red}0}&{\color{red}0}\\ 0&0&\sigma_3&{\color{red}0}&{\color{red}0} \end{pmatrix}\,. \] Notons \(\mathcal{B}_{\mathrm{can}}\) et \(\mathcal{B}_{\mathrm{can}}'\) les bases canoniques de \(\mathbb{R}^5\) et \(\mathbb{R}^3\): \[\begin{aligned} \mathcal{B}_{\mathrm{can}}&=\{\boldsymbol{e}_1,\boldsymbol{e}_2,\boldsymbol{e}_3,\boldsymbol{e}_4,\boldsymbol{e}_5\}\,,\\ \mathcal{B}_{\mathrm{can}}'&=\{ \boldsymbol{e}_1', \boldsymbol{e}_2', \boldsymbol{e}_3'\}\,. \end{aligned}\] On a des ''stretches'' pour les \(3\) premiers vecteurs de \(\mathcal{B}_{\mathrm{can}}\), \[ \Sigma\boldsymbol{e}_1=\sigma_1\boldsymbol{e}_1'\,,\quad \Sigma\boldsymbol{e}_2=\sigma_2\boldsymbol{e}_2'\,,\quad \Sigma\boldsymbol{e}_3=\sigma_3\boldsymbol{e}_3'\,,\quad \] mais les deux derniers sont tous envoyés sur le vecteur nul: \[ \Sigma\boldsymbol{e}_4= \Sigma\boldsymbol{e}_5= \boldsymbol{0}\,. \]
Remarque: Les relations ci-dessus, ''\(\Sigma\boldsymbol{e}_j=\sigma_j\boldsymbol{e}_j'\)'', rappellent celles du type ''\(A\boldsymbol{v}=\lambda\boldsymbol{v}\)''. La grande différence ici est que \(\boldsymbol{e}_j\) et \(\boldsymbol{e}_j'\) vivent dans des espaces différents!
Pour comprendre les relations entre les \(\boldsymbol{u}_k\), les \(\boldsymbol{v}_j\) et la matrice \(\Sigma\) (toujours en supposant que la décomposition \(A=U\Sigma V^T\) est déjà connue), on multiplie \(A\) par sa transposée pour obtenir une matrice de taille \(n\times n\) donnée par \[\begin{aligned} A^TA &=(U\Sigma V^T)^T(U\Sigma V^T)\\ &=V\Sigma^TU^TU\Sigma V^T \\ &=V(\Sigma^T\Sigma)V^T\,. \end{aligned}\] On a, dans le terme de droite, trois matrices de taille \(n\times n\). Puisque \(\Sigma^T\Sigma\) est diagonale, et puisque \(V^T\) est l'inverse de \(V\) (car cette dernière est orthogonale), on voit que ce produit de trois matrices carrées représente une diagonalisation de la matrice symétrique \(A^TA\). En particulier, les colonnes de \(V\) sont des vecteurs propres orthonormés de \(A^TA\), associés à des valeurs propres qui sont les éléments diagonaux de \(\Sigma^T\Sigma\), à savoir \(\sigma_i^2\): \[ (A^TA) \boldsymbol{v}_j=\sigma_j^2 \boldsymbol{v}_j\,, \qquad \forall j=1,\dots,n\,. \] De même pour \(AA^T\): c'est une matrice de taille \(m\times m\), et \[ AA^T=U(\Sigma\Sigma^T)U^T\,, \] qui implique que les colonnes de \(U\) sont des vecteurs propres orthonormés de \(AA^T\), associés à des valeurs propres qui sont les éléments diagonaux de \(\Sigma\Sigma^T\): \[ AA^T \boldsymbol{u}_k=\sigma_k^2 \boldsymbol{u}_k\,, \qquad \forall k=1,\dots,m\,. \]
Remarquons encore que dans les deux cas, les matrices diagonales
\(\Sigma^T\Sigma\) et \(\Sigma\Sigma^T\) ont des coefficients diagonaux donnés
par les carrés \(\sigma_i^2\).
Cette discussion montre que si une décomposition en valeurs singulières existe,
alors les matrices \(U\) et \(V\) se calculent en diagonalisant \(AA^T\) et
\(A^TA\).
(On verra comment simplifier un peu ce procédé par la suite.)
Ce qui n'est pas du tout démontré par l'argument ci-dessus, c'est si la
décomposition existe effectivement; nous le démontrerons dans la section
suivante.
Dans ce chapitre, nous définirons et manipulerons des matrices définies par blocs, ce qui signifie définies comme composées de sous-matrices. On utilisera l'indice ''\(\square\)'' pour indiquer qu'une matrice est définie par blocs.
Exemple: Avec \[ A= \begin{pmatrix} a&b&c\\ d&e&f \end{pmatrix} \,,\quad B= \begin{pmatrix} 1&2\\ 3&4 \end{pmatrix}\,, \] on peut définir \[ \left[ \begin{array}{cc} A&B \end{array} \right]_{\square} = \begin{pmatrix} a&b&c&1&2\\ d&e&f&3&4 \end{pmatrix}\,. \]
Les blocs qui composent une matrice par blocs doivent avoir des dimensions
compatibles.
Plus généralement, si l'on possède quatre matrices,
\[
A \text{ de taille } m\times k\,,\quad
B \text{ de taille }m\times l\,,\quad
C \text{ de taille } h\times k\,,\quad
D \text{ de taille } h\times l\,,
\]
on peut définir
Théorème: Soient \(A \in \mathbb{M}_{m \times n}(\mathbb{R})\) et \(B \in \mathbb{M}_{n \times m}(\mathbb{R})\), avec \(m \leqslant n\). Alors, les polynômes caractéristiques de \(AB\) et de \(BA\) satisfont \[ P_{BA}(\lambda) = \lambda^{n-m} P_{AB}(\lambda)\,. \]
On commence avec la preuve pour le cas \(m = n\). Soit \(r = \mathrm{rang}(A)\). Alors, il existe des matrices inversibles \(P, Q \in \mathbb{M}_{n \times n}(\mathbb{R})\) telles que \[ A = P \left[ \begin{array}{cc} I_r&\mathbf{0}\\ \mathbf{0}&\mathbf{0} \end{array} \right]_{\square} Q\,, \] où \(\mathbf{0}\) indiquée ci-dessus désigne la matrice nulle dans \(\mathbb{M}_{r \times (n-r)}(\mathbb{R})\), \(\mathbb{M}_{(n-r) \times r}(\mathbb{R})\) ou \(\mathbb{M}_{(n-r) \times (n-r)}(\mathbb{R})\), selon la position dans la matrice définie par blocs. On écrit aussi \[ B = Q^{-1} \left[ \begin{array}{cc} B_{1,1}&B_{1,2}\\ B_{2,1}&B_{2,2} \end{array} \right]_{\square} P^{-1}\,, \] où \(B_{1,1} \in \mathbb{M}_{r \times r}(\mathbb{R})\), \(B_{1,2} \in \mathbb{M}_{r \times (n-r)}(\mathbb{R})\), \(B_{2,1} \in \mathbb{M}_{(n-r) \times r}(\mathbb{R})\) et \(B_{2,1} \in \mathbb{M}_{(n-r) \times (n-r)}(\mathbb{R})\). Alors, \[ AB = P \left[ \begin{array}{cc} I_r&\mathbf{0}\\ \mathbf{0}&\mathbf{0} \end{array} \right]_{\square} Q Q^{-1} \left[ \begin{array}{cc} B_{1,1}&B_{1,2}\\ B_{2,1}&B_{2,2} \end{array} \right]_{\square} P^{-1} = P \left[ \begin{array}{cc} B_{1,1}&B_{1,2}\\ \mathbf{0}&\mathbf{0} \end{array} \right]_{\square} P^{-1}\,, \] ce qui nous dit que \(P_{AB}(\lambda) = (-\lambda)^{n-r}P_{B_{1,1}}(\lambda)\), vu que \[\begin{aligned} \det(AB-\lambda I_n) &= \det\left( P \left[ \begin{array}{cc} B_{1,1}&B_{1,2}\\ \mathbf{0}&\mathbf{0} \end{array} \right]_{\square} P^{-1} - P \left[ \begin{array}{cc} \lambda I_r&\mathbf{0}\\ \mathbf{0}&\lambda I_{n-r} \end{array} \right]_{\square} P^{-1} \right) \\ &= \det\left( P \left[ \begin{array}{cc} B_{1,1}-\lambda I_r&B_{1,2}\\ \mathbf{0}&-\lambda I_{n-r} \end{array} \right]_{\square} P^{-1}\right) \\ &= \det\left( \left[ \begin{array}{cc} B_{1,1}-\lambda I_r&B_{1,2}\\ \mathbf{0}&-\lambda I_{n-r} \end{array} \right]_{\square} \right) \\ &= (-\lambda)^{n-r} \det(B_{1,1}-\lambda I_r) \\ &= (-\lambda)^{n-r} P_{B_{1,1}}(\lambda)\,, \end{aligned}\] et \[ BA = Q^{-1} \left[ \begin{array}{cc} B_{1,1}&B_{1,2}\\ B_{2,1}&B_{2,2} \end{array} \right]_{\square} P^{-1} P \left[ \begin{array}{cc} I_r&\mathbf{0}\\ \mathbf{0}&\mathbf{0} \end{array} \right]_{\square} Q = Q^{-1} \left[ \begin{array}{cc} B_{1,1}&\mathbf{0}\\ B_{2,1}&\mathbf{0} \end{array} \right]_{\square} Q\,, \] ce qui nous dit que \(P_{AB}(\lambda) = (-\lambda)^{n-r}P_{B_{1,1}}(\lambda)\), vu que \[\begin{aligned} \det(BA-\lambda I_n) &= \det\left( Q^{-1} \left[ \begin{array}{cc} B_{1,1}&\mathbf{0}\\ B_{2,1}&\mathbf{0} \end{array} \right]_{\square} Q - Q^{-1} \left[ \begin{array}{cc} \lambda I_r&\mathbf{0}\\ \mathbf{0}&\lambda I_{n-r} \end{array} \right]_{\square} Q \right) \\ &= \det\left( Q^{-1} \left[ \begin{array}{cc} B_{1,1}-\lambda I_r&\mathbf{0}\\ B_{2,1}&-\lambda I_{n-r} \end{array} \right]_{\square} Q\right) \\ &= \det\left( \left[ \begin{array}{cc} B_{1,1}-\lambda I_r&\mathbf{0}\\ B_{2,1}&-\lambda I_{n-r} \end{array} \right]_{\square} \right) \\ &= (-\lambda)^{n-r} \det(B_{1,1}-\lambda I_r) \\ &= (-\lambda)^{n-r} P_{B_{1,1}}(\lambda)\,. \end{aligned}\] En conséquence, \(P_{AB}(\lambda) = (-\lambda)^{n-r} P_{B_{1,1}}(\lambda) = P_{BA}(\lambda)\), comme on voulait démontrer. On va démontrer le cas général. Soit \(\hat{A} \in \mathbb{M}_{m \times n}(\mathbb{R})\) la matrice obtenue de \(B\) en ajoutant \(n-m\) lignes nulles en bas de \(A\) et soit \(\hat{B} \in \mathbb{M}_{n \times m}(\mathbb{R})\) la matrice obtenue de \(B\) en ajoutant \(m-n\) colonnes nulles à droite de \(B\). En outre, on voit bien que \(\hat{B} \hat{A} = BA \in \mathbb{M}_{n \times n}(\mathbb{R})\) et \[ \hat{A} \hat{B} = \left[ \begin{array}{cc} AB &\mathbf{0}\\ \mathbf{0}&\mathbf{0} \end{array} \right]_{\square} \in \mathbb{M}_{n \times n}(\mathbb{R})\,. \] En conséquence, \[ P_{\hat{A} \hat{B}}(\lambda) = \det\left( \left[\begin{array}{cc} AB - \lambda I_m &\mathbf{0}\\ \mathbf{0}&- \lambda I_{n-m} \end{array} \right]_{\square} \right) = (-\lambda)^{m-n} \det(AB - \lambda I_m) = (-\lambda)^{m-n} P_{A B}(\lambda)\,. \] Alors, \[ P_{B A}(\lambda) = P_{\hat{B} \hat{A}}(\lambda) = P_{\hat{A} \hat{B}}(\lambda) = (-\lambda)^{m-n} P_{A B}(\lambda)\,, \] comme on voulait démontrer.
Dernière compilation: 2025-09-02 (09:33:31)
Sauf indication contraire, le contenu de ce document est soumis à une licence Creative Commons internationale, Attribution: Pas d'Utilisation Commerciale - Partage dans les Mêmes Conditions 4.0 (CC BY-NC-SA 4.0)
